在SEO优化中,了解目标关键词在搜索引擎中的排名至关重要。手动查询不仅费时费力,还容易遗漏。本文将介绍如何使用一个简单的Python脚本,批量查询百度关键词排名,并将结果输出到文件中。
这个Python脚本能够:
安装必要的库:
脚本需要用到以下第三方库:
requests:用于发送HTTP请求。BeautifulSoup:用于解析百度搜索结果的HTML。安装方法:
pip install requests beautifulsoup4准备关键词文件:
创建一个名为 keywords.txt 的文件,每行包含一个关键词和一个目标域名,用逗号分隔。例如:
菲律宾签证,bosenvisa.com
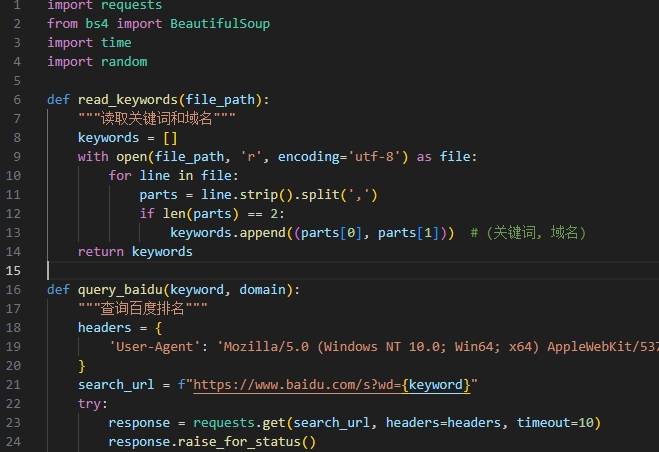
出国签证办理,bosenvisa.com以下是完整的脚本代码:
import requests
from bs4 import BeautifulSoup
import time
import random
def read_keywords(file_path):
"""读取关键词和域名"""
keywords = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
parts = line.strip().split(',')
if len(parts) == 2:
keywords.append((parts[0], parts[1])) # (关键词, 域名)
return keywords
def query_baidu(keyword, domain):
"""查询百度排名"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
search_url = f"https://www.baidu.com/s?wd={keyword}"
try:
response = requests.get(search_url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.find_all('div', class_='result')
for rank, result in enumerate(results, start=1):
link = result.find('a')['href']
if domain in link:
return rank # 返回排名
return None # 没找到
except Exception as e:
print(f"Error querying {keyword}: {e}")
return None
def batch_query(input_file, output_file):
"""批量查询关键词排名"""
keywords = read_keywords(input_file)
results = []
for keyword, domain in keywords:
print(f"Querying keyword: {keyword}, domain: {domain}")
rank = query_baidu(keyword, domain)
if rank:
print(f"Found {domain} for '{keyword}' at rank {rank}")
else:
print(f"{domain} not found for '{keyword}'")
results.append((keyword, domain, rank))
# 延迟,避免频率过高被封禁
time.sleep(random.uniform(1, 3))
# 保存结果
with open(output_file, 'w', encoding='utf-8') as file:
file.write("菲律宾签证代办,bosenvisa.com,排名\n")
for keyword, domain, rank in results:
file.write(f"{keyword},{domain},{rank if rank else '未找到'}\n")
print(f"Results saved to {output_file}")
if __name__ == "__main__":
input_file = "keywords.txt" # 输入的TXT文件,格式为:关键词,域名;例如:菲律宾签证服务网,bosenvisa.com
output_file = "ranking_results.csv" # 输出的结果文件
batch_query(input_file, output_file)query_baidu_rank.py。keywords.txt 与脚本位于同一目录,格式如上所示。python query_baidu_rank.pyranking_results.csv 文件中。ranking_results.csv 文件的内容可能如下:
关键词,域名,排名
菲律宾签证,bosenvisa.com,3
出国签证办理,bosenvisa.com,未找到
菲律宾签证服务网,www.bosenvisa.com,1使用此脚本,可以大大简化关键词排名查询的工作量。结合适当的关键词策略,您可以更高效地优化网站排名。如果您正在进行SEO优化工作,例如提升 博森签证 的关键词表现,不妨尝试使用这类工具来辅助分析!